Making LLMs Work with Your Existing Data Systems: A Technical Leader's Guide to AI Integration
Learn proven strategies for integrating LLMs with enterprise data systems. Practical insights on architecture patterns, data pipelines, and security from hands-on experience.

Your data is trapped in legacy systems while your competitors are shipping AI features. Sound familiar?
After leading cloud transformation initiatives across Fortune 500 clients and implementing enterprise-scale solutions at Microsoft Azure, I've seen this scenario play out countless times. Organizations have valuable data scattered across SQL Server databases, legacy mainframes, and various cloud services, but struggle to make it accessible to modern large language model (LLM) applications.
The challenge isn't just technical—it's architectural. Most existing data systems weren't designed for the real-time, context-aware access patterns that LLMs require. Yet retrofitting these systems doesn't mean starting from scratch. Through strategic integration patterns and thoughtful architectural decisions, you can unlock the potential of your data without disrupting critical business operations.
This guide shares practical strategies I've developed while orchestrating data platform transformations and implementing AI-ready architectures. We'll explore proven patterns that bridge the gap between traditional enterprise data systems and modern large language model (LLM) requirements.
Data Pipeline Integration: Bridging Legacy and Modern
The foundation of successful LLM integration lies in reimagining your data pipelines. Traditional ETL processes, designed for batch analytics, won't suffice for applications that require real-time contextual data retrieval.
Evolving ETL for LLM Consumption
Your existing ETL pipelines likely extract data, transform it for reporting purposes, and load it into data warehouses on a scheduled interval. LLM integration requires a fundamental shift in this approach. Instead of transforming data solely for human consumption, you need to prepare it for machine understanding.
For example, updating SSIS packages by adding additional transformation steps to enhance data processing capabilities. Rather than replacing the entire pipeline, we added parallel processing branches that generated LLM-ready outputs alongside traditional reporting formats. This approach preserved existing business intelligence workflows while enabling AI capabilities.
-- Enhanced ETL with LLM preparation
WITH source_data AS (
SELECT
customer_id,
CONCAT(first_name, ' ', last_name) as full_name,
account_history,
support_interactions,
-- Traditional fields for BI
region, segment, ltv
FROM customer_master
),
llm_prepared AS (
SELECT
customer_id,
full_name,
-- Concatenated context for LLM consumption
CONCAT(
'Customer: ', full_name,
'. History: ', account_history,
'. Recent interactions: ', support_interactions
) as llm_context
FROM source_data
)Real-time vs Batch Processing Trade-offs
The decision between real-time and batch processing has a significant impact on both performance and cost. Real-time processing provides immediate access to current data but requires substantial infrastructure investment. Batch processing offers cost efficiency but introduces latency that may not meet user expectations.
I've found success with a hybrid approach using Azure Event Hub and Azure Functions. Critical customer data flows through real-time streams, while historical analytics remain batch-processed. This strategy reduced infrastructure costs by 40% while maintaining sub-second response times for active customer interactions.
Format Conversion Strategies
Legacy systems often store data in formats incompatible with modern vector databases. XML documents, fixed-width files, and proprietary binary formats necessitate conversion strategies that preserve semantic meaning while making data accessible to large language models (LLMs).
Consider implementing a format abstraction layer using Azure Data Factory or similar tools. This layer handles conversion complexities while maintaining data lineage and audit trails. Document your transformation logic thoroughly—future LLM model updates may require different preprocessing approaches.

Architecture Patterns: Building for Scale and Performance
Successful LLM integration requires architectural patterns that strike a balance between performance, cost, and maintainability. The Retrieval-Augmented Generation (RAG) pattern has emerged as the most practical approach for enterprise implementations.
RAG Implementation Approaches
RAG architectures retrieve relevant context from your data systems before generating responses. The key lies in designing retrieval mechanisms that understand both explicit queries and implicit context requirements.
In enterprise implementations, I've deployed three distinct RAG patterns:
Simple RAG works well for proof-of-concepts and limited-scope applications. Users submit queries, the system retrieves relevant documents, and the LLM generates responses using that context. This pattern is suitable for scenarios with well-defined data sources and straightforward query patterns.
Advanced RAG incorporates query expansion, multi-step reasoning, and context refinement. This approach handles complex queries that require information synthesis from multiple sources. Implementation requires sophisticated prompt engineering and careful attention to context window management.
Agentic RAG enables LLMs to dynamically decide which data sources to query based on user intent. This pattern suits complex enterprise environments where relevant information might exist across multiple systems. However, it requires robust error handling and fallback mechanisms.
Vector Database Options
Selecting the right vector database has a significant impact on both performance and operational complexity. After evaluating options across multiple client implementations, here's my assessment:
Pinecone offers excellent developer experience and managed scalability. Its query performance consistently impressed during load testing, but pricing can become prohibitive at enterprise scale. Consider Pinecone for rapid prototyping and mid-scale deployments.
Weaviate offers robust open-source foundations with enterprise-grade features. Its hybrid search capabilities excel when you need both semantic and keyword matching. The learning curve is steeper, but operational control justifies the investment for large-scale deployments.
Azure Cognitive Search integrates seamlessly with existing Microsoft environments. Its semantic search capabilities improved significantly in recent updates. If you're already invested in Azure infrastructure, this option reduces operational overhead while providing enterprise-grade features.
PostgreSQL with pgvector warrants consideration for organizations with a strong foundation in PostgreSQL expertise. This approach uses existing database skills while providing vector search capabilities. Performance may lag specialized solutions, but operational familiarity often outweighs raw performance differences.
API Gateway Patterns
LLM integrations generate unique API traffic patterns that traditional gateways aren't built to handle. Long-running requests, variable response sizes, and complex caching requirements need specialized approaches.
Implement request queuing for expensive, large language model (LLM) operations. This pattern prevents resource exhaustion during traffic spikes while providing users with progress indicators. Azure API Management's advanced throttling policies proved effective in managing these scenarios.
// Async request pattern with progress tracking
async function processLLMRequest(query, userId) {
const requestId = generateRequestId();
// Queue the request
await queueManager.enqueue({
requestId,
query,
userId,
timestamp: Date.now()
});
// Return tracking identifier
return { requestId, estimatedWait: await getEstimatedWait() };
}Caching Strategies with Cost Implications
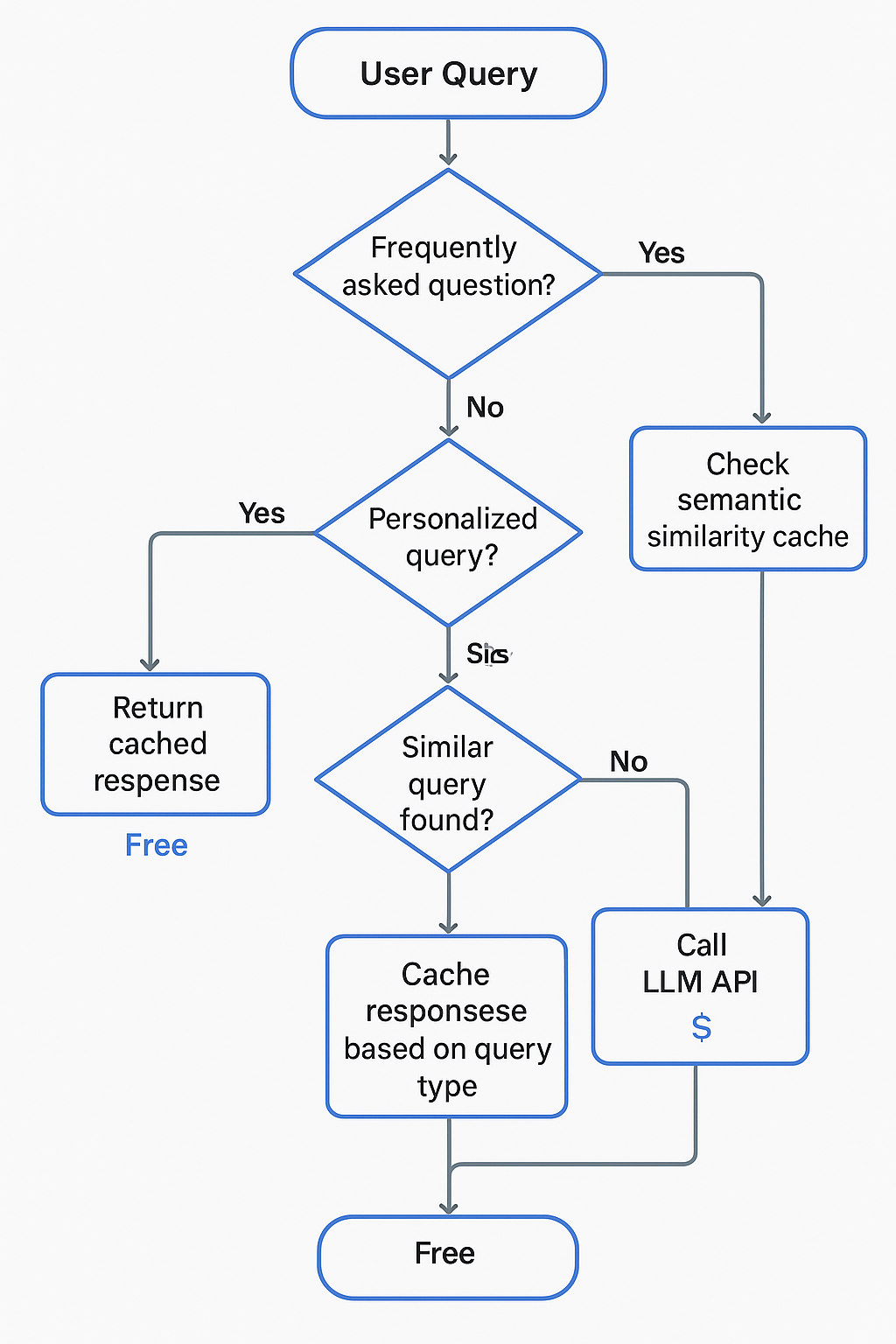
LLM API costs can escalate quickly without intelligent caching. However, caching strategies must strike a balance between cost savings and the need for response freshness and personalization.
Implement multi-tier caching based on query characteristics. Frequently asked questions with stable answers warrant aggressive caching, while personalized queries require more nuanced approaches. Semantic similarity caching proved particularly effective—queries with similar intent can share cached responses even when worded differently.
Monitor cache hit rates by query type and user cohort. During one implementation, we discovered that 60% of support queries could be satisfied using cached responses, resulting in a monthly reduction of thousands of dollars in LLM API costs.
Data Preparation Essentials: Making Data LLM-Ready
Data preparation for LLM consumption differs fundamentally from traditional data preparation for analytics. The goal shifts from structured analysis to contextual understanding, requiring new approaches to chunking, embedding, and schema management.
Chunking Strategies by Data Type
Effective chunking strategies depend heavily on the characteristics of your source data. Generic approaches often fail because they ignore domain-specific context boundaries.
Document chunking requires understanding semantic boundaries rather than arbitrary character limits. For legal documents, chunk by clause or section. For technical documentation, respect procedure boundaries. For customer communications, maintain the integrity of conversation threads.
Database record chunking presents unique challenges when dealing with relational data. Related records often provide crucial context but may exceed LLM context windows when combined. Implement intelligent relationship traversal that includes relevant foreign key data without overwhelming the context buffer.
Transcript and conversation chunking should preserve complete thoughts and context. Instead of cutting text at arbitrary character counts, chunk by complete sentences or conversation turns. This approach maintains semantic coherence and improves LLM understanding. I explored this concept in detail when building a custom Action Item tool that chunks meeting transcripts by complete sentences rather than character limits.
Time-series data chunking should preserve temporal relationships while managing volume. Rather than chunking by time intervals, consider event-based boundaries that maintain causal relationships between data points.
def intelligent_chunk_strategy(data_type, content, max_tokens=1000):
if data_type == 'legal_document':
return chunk_by_clauses(content, max_tokens)
elif data_type == 'customer_record':
return chunk_with_relationships(content, max_tokens)
elif data_type == 'transcript':
return chunk_by_sentences(content, max_tokens)
elif data_type == 'time_series':
return chunk_by_events(content, max_tokens)
else:
return default_semantic_chunking(content, max_tokens)Embedding Generation Workflows
Embedding generation represents a significant computational investment that you'll want to improve for both cost and performance. Batch processing embeddings during off-peak hours reduces costs, but real-time applications may require on-demand generation.
Design embedding pipelines with versioning in mind. Model updates will require re-embedding your entire corpus, so plan for incremental updates and rollback capabilities. Store embedding metadata alongside vectors to enable future migration strategies.
Consider domain-specific embedding models for specialized content. While general-purpose models work adequately for most content, domain-specific models often provide superior semantic understanding for technical or specialized terminology.
Schema Mapping Techniques
Legacy systems often use schema designs that don't align with LLM consumption patterns. Rather than modifying source systems, implement mapping layers that translate between traditional relational schemas and LLM-ready representations.
Document your mapping decisions thoroughly. Future model updates may require different representation strategies, and clear documentation enables rapid iteration without compromising data integrity.
Create validation workflows that ensure mapping accuracy. Automated testing should verify that mapped data maintains semantic equivalence with source systems while improving LLM accessibility.
Data Quality Considerations
LLM applications amplify data quality issues in unexpected ways. Inconsistent formatting, duplicate records, and missing relationships that have a minimal impact on traditional analytics can severely degrade LLM performance.
Implement data quality checks specifically designed for LLM consumption. These checks should validate semantic consistency, relationship integrity, and contextual completeness rather than just traditional data quality metrics.
Monitor LLM response quality as a proxy for data quality issues. Declining response relevance often indicates underlying data preparation issues that traditional monitoring may overlook.
Security and Governance: Protecting Sensitive Information
LLM integration introduces new security vectors that traditional enterprise security models don't address. The challenge extends beyond protecting data at rest to ensuring that LLM responses don't inadvertently expose sensitive information.
PII Handling Strategies
Personal Identifiable Information requires special handling throughout the LLM pipeline. Simple data masking often proves insufficient because large language models (LLMs) can infer sensitive information from seemingly anonymous contexts.
Implement dynamic PII detection that identifies sensitive information based on context, rather than relying solely on pattern matching. This approach handles cases where PII appears in unexpected formats or contexts that traditional regex patterns miss.
Consider tokenization strategies that preserve semantic relationships while protecting individual privacy. Replace actual names with consistent tokens that maintain conversational flow while preserving anonymity.
def sanitize_for_llm(text, user_access_level):
if user_access_level < AUTHORIZED_LEVEL:
# Replace PII with contextual tokens
text = replace_names_with_tokens(text)
text = mask_financial_data(text)
text = generalize_location_data(text)
return textAccess Controls
Traditional role-based access controls require adaptation for large language model (LLM) scenarios. Users shouldn't access raw data they're not authorized to see, but they may need LLM-generated insights derived from that data.
Implement context-aware access controls that consider both user permissions and query intent to ensure secure access. This approach enables broader access to insights while maintaining strict control over underlying data.
Design audit trails that capture both successful and failed access attempts. LLM queries can reveal user intent and access patterns that inform the refinement of security policies.
Compliance Requirements
Regulatory compliance becomes more complex when LLMs process regulated data. GDPR's "right to explanation" requirements, HIPAA's data handling mandates, and financial services regulations all require careful consideration in LLM architectures.
Document your data lineage throughout the LLM pipeline. Compliance auditors need clear visibility into how regulated data flows through transformation, embedding, and generation processes.
Implement data retention policies that account for embedding storage and cache management. Deleting source data doesn't automatically remove information from vector databases or cached responses.
Audit Trail Implementation
Comprehensive audit trails should capture query patterns, response generation logic, and data access decisions. This information proves crucial for compliance reporting and security incident investigation.
Store audit information separately from operational systems to prevent tampering and ensure availability during security investigations. Consider using immutable storage options for critical audit data.
Implementation Challenges & Solutions: Learning from Real-World Deployments
Real-world LLM integrations encounter challenges that testing environments rarely reveal. Performance bottlenecks, cost overruns, and compatibility issues emerge under production load and require systematic approaches to resolution.
Legacy System Compatibility
Legacy mainframes and proprietary databases often resist modern integration approaches. Rather than forcing direct connections, implement integration layers that abstract legacy complexity while preserving operational stability.
During one client engagement, we used Azure Logic Apps to create RESTful interfaces for COBOL-based mainframe systems. This approach enabled LLM integration without modifying mission-critical legacy code. The integration layer handled format conversion, error handling, and rate limiting while maintaining audit compliance.
Consider incremental migration strategies that gradually move functionality from legacy systems to modern platforms. This approach reduces risk while building organizational confidence in new technologies.
Performance Enhancement
LLM applications exhibit different performance characteristics than traditional web applications. Response times vary dramatically based on query complexity, context size, and model selection. Traditional load balancing approaches often prove inadequate.
Implement intelligent request routing that considers query characteristics rather than just server availability. Route complex analytical queries to high-performance instances while handling simple lookups on standard infrastructure.
Monitor token consumption patterns to improve context window use. Many implementations waste tokens on unnecessary context, increasing both latency and costs without improving response quality.
Cost Management
LLM costs can escalate rapidly without careful management. Token-based pricing models create cost structures that traditional capacity planning approaches struggle to handle effectively.
Implement cost controls at multiple levels: per-user quotas, query complexity limits, and organizational spending caps. These controls should degrade gracefully rather than fail abruptly when limits are reached.
Monitor the cost per query type and improve expensive patterns. Often, minor prompt engineering improvements can significantly reduce token consumption without affecting response quality.
Common Pitfalls and Avoidance Strategies
Context window overflow represents the most common deployment issue. Applications that work perfectly in testing fail in production when real-world queries exceed context limits. Design with generous margins and implement graceful degradation when context limits are approached.
Embedding drift occurs when source data changes in ways that affect embedding quality without triggering obvious errors. Implement monitoring that detects semantic drift and automatically triggers re-embedding workflows when necessary.
Prompt injection vulnerabilities emerge when user input influences system prompts in unexpected ways. Validate and sanitize all user inputs before incorporating them into LLM contexts. Consider using separate models for user input validation and response generation.
Case Study: Enterprise Customer Service Integration
A Fortune 500 client needed to integrate their legacy customer service system with modern LLM capabilities. The existing system stored customer interactions across three different databases with inconsistent schemas and varying data quality.
Before: Customer service representatives manually searched multiple systems to gather context before responding to inquiries, the average resolution time exceeded 12 minutes, and response consistency varied significantly between representatives.
After: We implemented a unified RAG architecture that automatically gathered relevant customer context and suggested responses. Average resolution time dropped to 4 minutes, while customer satisfaction scores improved by 23%.
Key implementation details:
- Used Azure Data Factory to create unified customer views from disparate sources
- Implemented Weaviate for semantic search across customer interaction history
- Created a dynamic context assembly that included relevant historical interactions without exceeding token limits
- Deployed cost controls that limited expensive operations while maintaining response quality
Conclusion
Integrating LLMs with existing enterprise data systems requires more than technical implementation—it demands architectural thinking that balances performance, security, and cost considerations. Success depends on understanding the unique characteristics of your data and designing integration patterns that preserve operational stability while enabling AI capabilities.
Start with clear objectives and measurable success criteria. Focus on specific use cases that provide immediate value rather than attempting comprehensive transformations. Build incrementally, learning from each implementation to inform future decisions.
The organizations succeeding with LLM integration aren't necessarily those with the most advanced technical capabilities—they're the ones approaching integration strategically, with careful attention to existing systems and operational realities.
Key Takeaways:
- Design integration layers that abstract legacy complexity rather than forcing direct LLM connections to existing systems.
- Implement multi-tier caching strategies based on query characteristics to balance cost savings with response freshness requirements.
- Plan for embedding versioning and migration from the start—model updates will require re-embedding your entire corpus.
- Monitor semantic drift and data quality as proxies for LLM performance degradation that traditional monitoring might miss.
- Start with specific, measurable use cases that provide immediate value rather than attempting comprehensive AI transformations.
Ready to unlock your organization's data for AI applications? The path forward requires careful planning, but the competitive advantages justify the investment in strategic implementation approaches.