The Organizational Capability Map: Deciding What Your AI Agents Should Actually Own
Most AI deployments fail not because the technology doesn't work, but because nobody decided which workflows agents should actually own. The Organizational Capability Map is a framework for making that call.

Klarna deployed an AI agent into customer service and saved $60 million. Then they walked it back and started rehiring humans. Microsoft pushed Copilot across every Office application, and only 5% of organizations moved past pilot. In both cases, the technology worked. The organizational decision about where to deploy it didn't.
The common thread isn't AI failure. It's deployment without a map. Nobody had a systematic framework for deciding which workflows agents should own autonomously, which they should augment, and which should stay human. The result is what I described in the first post in this series: capable AI pointed at the wrong targets because nobody built the infrastructure to aim it.
This post introduces the framework for building that map.
Why You Need a Map Before You Deploy
Most enterprises I work with take one of two approaches to AI deployment. The first is the top-down mandate: leadership announces an AI strategy, a budget gets allocated, and teams scramble to find use cases that justify the spend. The second is bottom-up proliferation: individual teams adopt AI tools independently, and nobody has visibility into what's actually running, what data it's touching, or what decisions it's making.
Both approaches skip the same step. Neither one asks: for each workflow we're considering, what level of AI autonomy is appropriate given the stakes, the ambiguity, and our organizational readiness?
Without answering that question, you get predictable failure modes. Agents deployed into high-stakes workflows before the organization has built the trust and guardrails to support them. Human oversight layered onto low-stakes workflows where it adds cost without adding value. And a growing shadow agent problem where employees build their own AI workflows because the official approach is either too slow or too restrictive.
An Organizational Capability Map is the answer. It's a living document that categorizes every workflow in your organization into one of three tiers based on a structured evaluation. Not a one-time audit. A system that evolves as agent capabilities mature, as your intent engineering infrastructure improves, and as the organization builds confidence through demonstrated results.
Three Tiers of AI Autonomy
The framework categorizes workflows into three tiers. The boundaries between them aren't fixed. They're a function of your organization's current capabilities, and they should shift over time.
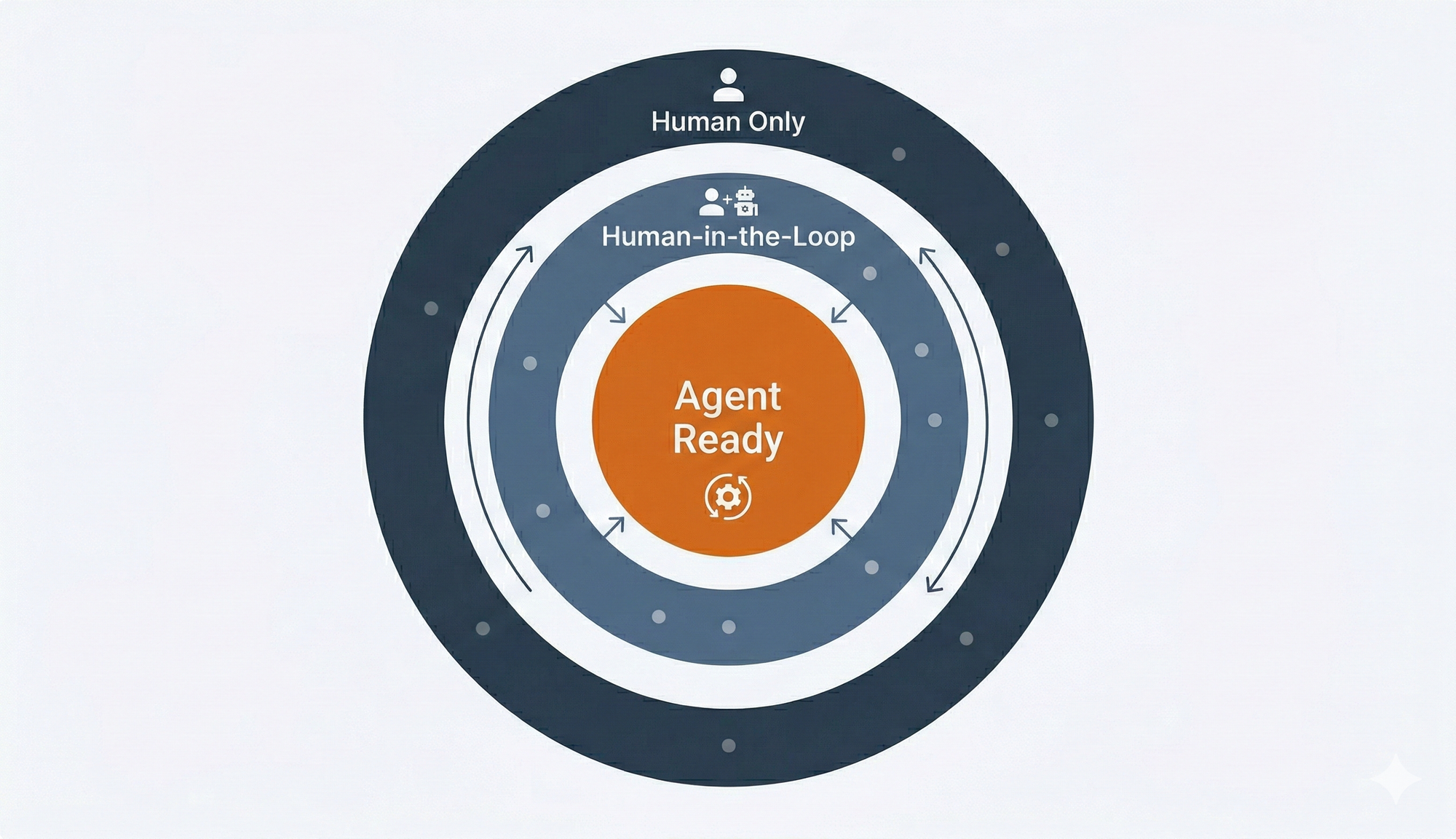
Agent Ready
These are workflows where an agent can operate autonomously within defined guardrails. The success criteria are measurable. The decision boundaries are clear. The consequences of a wrong decision are contained and reversible.
Examples: internal document summarization, first-pass data quality checks, routine report generation, standard customer inquiry routing, code review triage. These workflows share a common trait. The cost of a mistake is low, the feedback signal is fast, and a human can review the output without reconstructing the entire decision chain.
Agent Ready doesn't mean unsupervised. It means the supervision can be asynchronous. Spot-check the outputs. Monitor the metrics. Intervene when something drifts. But the agent drives.
Human-in-the-Loop
These are workflows where agents add significant value but humans retain decision authority at critical points. The agent does the analysis, surfaces recommendations, drafts the output. A human reviews and approves before anything goes live.
Examples: customer escalation handling, content creation for external audiences, vendor evaluation, hiring pipeline screening, financial forecasting. These workflows involve ambiguity that current AI handles unevenly: reading emotional context, weighing competing stakeholder interests, applying institutional knowledge that hasn't been codified.
The trap here is treating Human-in-the-Loop as "the agent does the work and a human rubber-stamps it." That's not augmentation. That's automation with plausible deniability. Real Human-in-the-Loop means the human is making a genuine judgment call at the decision point, with full context about what the agent did and why.
Human Only
These are workflows where human judgment is non-negotiable. The decisions are high-stakes and irreversible. The context is deeply ambiguous. The regulatory, ethical, or relationship implications require a level of accountability that can't be delegated to a system.
Examples: executive hiring decisions, crisis communications, legal strategy, major contract negotiations, safety-critical system overrides. These workflows share a feature: the cost of getting it wrong is existential or near-existential for the relationship, the product, or the company.
Human Only is not a permanent designation. It's a current assessment. Five years ago, nobody would have classified customer service as agent-ready. Capabilities evolve. Organizational trust grows. The point of the map is to make these transitions deliberate rather than accidental.
Six Dimensions for Evaluating Workflows
The question every organization needs to answer is: how do we decide which tier a workflow belongs in? Not by gut feel. Not by which team lobbied hardest. By structured evaluation across six dimensions.
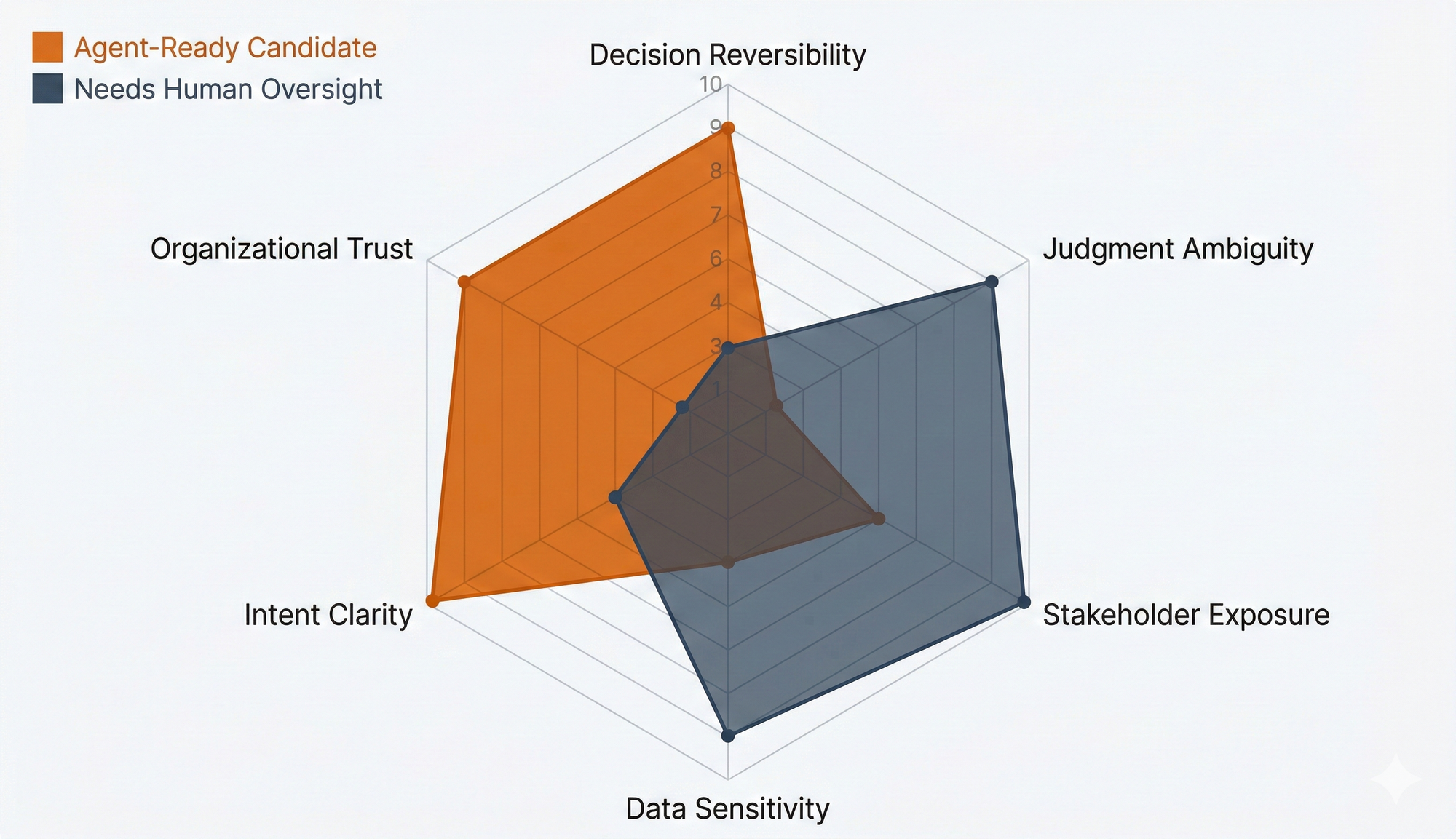
1. Decision Reversibility
Can the agent's decision be undone if it's wrong?
A draft email that goes through human review before sending is fully reversible. An automated vendor payment that clears within minutes is not. A customer service response that's sent instantly falls somewhere in between: you can follow up, but you can't unsend it.
Workflows with irreversible decisions need more human oversight. This seems obvious, but I've watched organizations deploy agents into irreversible workflows because the task itself seemed simple. Simple and reversible are different dimensions. An agent can perform a simple task flawlessly and still cause irreversible damage if the task was the wrong one to perform.
2. Judgment Ambiguity
How much does the workflow depend on reading between the lines?
A compliance check against a defined rule set is low ambiguity. Deciding whether to bend a return policy for a long-term customer is high ambiguity. Determining whether a contract clause represents acceptable risk requires judgment that depends on organizational context an agent doesn't have.
High ambiguity doesn't automatically mean Human Only. It means the organization needs to ask: have we codified enough of our institutional judgment into structured decision logic that an agent can handle the common cases? If yes, Human-in-the-Loop with clear escalation paths may work. If no, you're not ready.
3. Stakeholder Exposure
Who sees the agent's output?
Internal-only workflows have a natural safety net. If an agent produces a bad summary of meeting notes, someone on the team catches it. Customer-facing workflows raise the stakes. Regulator-facing workflows raise them further. Board-level or public-facing outputs carry reputational risk that compounds fast.
The evaluation isn't just "who sees it" but "what happens if the output is wrong and the wrong person sees it." An internal dashboard error gets corrected. A wrong number in a regulatory filing triggers an investigation.
4. Data Sensitivity
What data is the agent touching?
An agent summarizing public product documentation operates in a low-sensitivity environment. An agent processing customer PII, financial records, or health data operates under regulatory constraints that limit what it can do, where it can send outputs, and who can audit its decisions.
This dimension isn't just about privacy regulations. It's about the blast radius of a data handling mistake. An agent that accesses compensation data across the organization has a different risk profile than one that accesses a team's project board, even if neither involves external PII.
5. Intent Clarity
How well-defined are the success criteria?
"Respond to customer inquiries within SLA" is clear enough to measure. "Improve the quality of our product recommendations" is not, at least not without decomposing it into specific, measurable signals. If you can't articulate what "good" looks like in terms an agent can optimize against, the workflow isn't agent-ready. Full stop.
This is where the intent gap from the first post becomes operational. A workflow might score well on every other dimension but fail here because the organization hasn't done the work to translate its goals into measurable, machine-actionable criteria. That's not a technology problem. It's a clarity problem. And it's the most common reason workflows that look agent-ready on paper aren't.
6. Organizational Trust Maturity
Has the team built enough confidence through smaller deployments to support this level of autonomy?
This is the dimension most organizations skip. A workflow might score perfectly on the first five dimensions: reversible decisions, low ambiguity, internal-only exposure, no sensitive data, clear success criteria. But if the team responsible for it has never worked with an AI agent before, deploying it as Agent Ready is a mistake.
Trust is built through demonstrated results. Start with Human-in-the-Loop. Let the team see the agent work. Let them catch its mistakes and understand its patterns. Then graduate to Agent Ready once the team has internalized when the agent is reliable and when it needs intervention. This progression isn't overhead. It's how organizations avoid Klarna's mistake at scale.
Putting It Together: Vendor Invoice Processing
Frameworks are only useful if you can run a real workflow through them. Take vendor invoice processing, a workflow that most enterprises are eager to automate because it's high-volume, repetitive, and expensive to staff.
On the surface, it looks Agent Ready. The inputs are structured (invoices follow predictable formats), the rules seem clear (match the PO, check the amounts, route for approval), and the task is repetitive enough that an agent should handle it easily.
Run it through the six dimensions and a different picture emerges.
Decision Reversibility: Low. Once a payment clears, reversing it requires vendor coordination, accounting adjustments, and sometimes legal involvement. A batch of incorrect payments on a Friday afternoon compounds before anyone catches it Monday morning.
Judgment Ambiguity: Medium. Most invoices are straightforward, but the exceptions matter. A line item that's 15% over the PO estimate might be a legitimate change order or a billing error. An agent without context about the vendor relationship or the project scope can't tell the difference.
Stakeholder Exposure: Internal, but the blast radius extends to vendor relationships. Consistent underpayments damage trust. Overpayments create audit problems. Neither stays internal for long.
Data Sensitivity: Moderate. The agent accesses financial records, vendor banking details, and internal budget allocations. Not customer PII, but enough to cause real damage if mishandled.
Intent Clarity: High for the routine cases. Match the PO, verify the amounts, route to the right approver. But "the right approver" depends on dollar thresholds, budget owners, and exception paths that change quarterly.
Organizational Trust Maturity: This is where it gets honest. Has the accounts payable team ever worked with an AI agent on anything? If not, deploying one into a workflow that touches every vendor relationship the company has is a bad place to start.
The verdict: Human-in-the-Loop. The agent handles matching, flagging discrepancies, and routing. A human reviews exceptions and approves payments above a threshold. After three months of demonstrated accuracy on the routine cases, the team has the evidence to move the routine tier to Agent Ready while keeping exceptions in Human-in-the-Loop.
That's the map in action. Not a binary yes-or-no on automation, but a structured assessment that leads to a defensible deployment decision with a clear path for evolution.
How the Map Evolves
A static capability map is almost as dangerous as no map at all. The whole point of the three-tier framework is that workflows move between tiers as conditions change.
Three forces drive that movement.
Agent capabilities improve. A workflow that required Human-in-the-Loop last quarter might become Agent Ready this quarter because the model improved, the context infrastructure matured, or the organization built better guardrails. Conversely, a workflow that was Agent Ready might need to move back if new edge cases surface that the agent handles poorly.
Organizational context shifts. A new regulation changes the compliance requirements for a workflow. A company acquisition brings new customer segments with different expectations. A strategic pivot changes which outcomes matter most. Any of these can change the appropriate autonomy tier for a workflow overnight.
Trust grows through experience. This is the most important one. When a team has operated a workflow in Human-in-the-Loop mode for three months and the agent's recommendations were right 98% of the time, the case for moving to Agent Ready becomes evidence-based rather than theoretical. The map should have a defined process for these transitions: who proposes the change, what evidence is required, who approves it.
Who Owns the Map
This is where most organizations stall. The capability map sits at the intersection of engineering, operations, strategy, and risk. No single function owns all of those, which is exactly the translation gap that makes AI deployments fail in the first place.
The map is the artifact that forces the strategy people and the builder people into the same room. Somebody needs to own it. Not a committee. Not a working group that meets quarterly. A person or a small team with cross-functional authority who is accountable for maintaining the map, facilitating tier transitions, and ensuring that every AI deployment has a clear place on it.
The title doesn't matter. The authority does. This function needs the mandate to tell an engineering team "this workflow isn't ready for Agent Ready" and the credibility to tell a business leader "this workflow is ready to graduate from Human-in-the-Loop." Without both, the map becomes a document that nobody updates and everybody ignores.
What This Makes Possible
The capability map solves a problem that kills most enterprise AI programs: the absence of a shared language for deployment decisions. Without it, every conversation about "should we use AI for this?" devolves into a debate between the optimists who want to automate everything and the skeptics who trust nothing. The map replaces opinion with structured assessment. When a VP asks "why aren't we using AI for this workflow?", the answer points to specific dimensions that need to change, not to vague concerns about readiness.
But the map also reveals a harder question. Once you've decided where agents should operate, you need to define what they're optimizing for in each of those workflows. The vendor invoice agent isn't just "processing invoices." It's making judgment calls about matching tolerances, exception routing, and approval thresholds that reflect organizational priorities the agent was never explicitly told about.
That's the gap between knowing where to deploy and knowing how to aim. Closing it requires translating organizational goals into forms that agents can actually act on: Goal Translation Infrastructure and Agent Actionable Objectives. That's the final post in this series, and it's where the three layers of intent engineering come together.
This is the second post in a three-part series on Intent Engineering and organizational readiness for agentic AI. Next: Goal Translation Infrastructure and Agent Actionable Objectives, the framework for encoding what your organization actually wants into forms that agents can act on.
If you're working through where AI agents belong in your organization, I'd like to hear how you're approaching it. Find me on LinkedIn or reach out at jonathan@jonathangardner.io.