The Most Common Mistakes in Cloud Migration Projects
One bad call killed 2.5M connected cars. 75% of cloud migrations fail because teams assume apps work the same in cloud. They don't. Here are the 10 costliest mistakes and how to dodge them.


A single architecture decision took down 2.5 million connected vehicles.
I was part of the AzureCAT team when this automotive customer called. Their connected vehicle platform worked fine with 200,000 cars. But at 2.5 million vehicles, one failed component brought down the entire fleet.
The problem? They assumed their application would behave the same in the cloud as it did on-premises. They didn't build stamp architecture for scale-out. When one stamp failed, everything went down.
This wasn't a freak accident. It was predictable. Cloud has different constraints than your data center. Storage proximity matters. API endpoint query limits bite you. Network patterns change everything.
Most migration advice comes from consultants who sell projects. I've actually run these projects for Fortune 500 companies and fixed them when they break at massive scale. I've seen the expensive mistakes firsthand.
Here are the 10 mistakes I see most often, and how to avoid them.
Why Most Cloud Migrations Fail
75% of cloud migrations run behind schedule. 38% blow their budgets. The average outage costs $1.9 million per hour.
These aren't small companies learning hard lessons. These are Fortune 100 firms with dedicated cloud teams and million-dollar consulting contracts.
The problem isn't technical complexity. It's assumptions. Companies treat cloud migration like moving furniture to a bigger house. But cloud isn't just more space. It's a different operating model.
The 10 Most Common Mistakes
1. Lift-and-Shift Everything As-Is
Why it seems smart: Move fast without code changes. Get to cloud quickly and modernize later.
Why it fails: Legacy application quirks follow you to the cloud. Costs soar because you're running data center patterns on cloud infrastructure. You miss every modernization benefit.
Do this instead: Triage your applications first. Retire what you can. Re-platform your hot workloads. Only lift-and-shift your stable, low-change systems.
2. One Giant VPC Without a Landing Zone
Why it seems smart: Simple network design. Everything can talk to everything. Easy to start.
Why it fails: No separation between environments. Flat security model creates trust issues. IAM becomes a tangled mess. One breach affects everything.
Do this instead: Build your landing zone first. Separate accounts for production, development, and shared services. Design your network before you need it.
3. "We'll Add Infrastructure as Code Later"
Why it seems smart: Move now, automate later. Don't slow down the migration with tooling.
Why it fails: Configuration drift starts immediately. Snowflake servers pile up. Manual changes block rollbacks. You can't reproduce environments.
Do this instead: Write Terraform or Bicep templates from day one. No manual changes in production. Ever.
4. Buying Multi-Year Reserved Instances Before Baselining
Why it seems smart: Lock in discounts immediately. Show cost savings to executives.
Why it fails: You're guessing at capacity needs. Wrong instance sizes get locked for years. You pay for resources you can't use.
Do this instead: Run on-demand for 60-90 days. Baseline your actual usage patterns. Then buy reservations that match reality.
5. Multi-Cloud Abstraction for Everything
Why it seems smart: Avoid vendor lock-in. Keep options open. Use best-of-breed services.
Why it fails: You get lowest-common-denominator features. Teams move slower because they can't use native services. Complexity explodes.
Do this instead: Pick a primary cloud and use its native services. Multi-cloud makes sense for specific workloads, not everything.
6. Cloning Your On-Premises Security Model
Why it seems smart: Use familiar security rules. Don't change what works.
Why it fails: Perimeter security becomes brittle in cloud. Broad network access creates large blast radius. Legacy firewall rules don't map to cloud constructs.
Do this instead: Start with identity-first, zero-trust principles. Assume breach and limit lateral movement.
7. Re-Using On-Premises Monitoring Tools
Why it seems smart: Keep familiar dashboards. Don't retrain the team on new tools.
Why it fails: You get blind spots on auto-scaling resources. Can't see cloud-native metrics. Miss optimization opportunities.
Do this instead: Enable cloud-native monitoring first. Map your key metrics to new tools. Train your team on cloud observability.
8. Ignoring Data Transfer and Egress Charges
Why it seems smart: Storage costs look cheap in cloud pricing calculators.
Why it fails: Cross-availability-zone data movement dominates your bill. Egress charges surprise you at month-end. Chatty applications become expensive.
Do this instead: Keep data close to compute. Design for data locality. Monitor transfer costs from day one.
9. Treating Stateful and Stateless Services the Same
Why it seems smart: Uniform deployment pipelines. Consistent operational model.
Why it fails: Stateful services need different backup strategies. Scaling patterns differ. Recovery procedures are more complex.
Do this instead: Split your data plane from your compute plane. Handle stateful services as special cases.
10. Moving Huge Monolithic Databases As-Is
Why it seems smart: Single migration step. No application changes needed.
Why it fails: You hit vertical scaling limits quickly. Cut-over becomes high-risk big-bang event. Performance tuning gets harder.
Do this instead: Break databases by business domain. Archive cold data first. Plan incremental migration strategies.
What Executives Think vs. What Engineers Know
Leadership often has different assumptions than the technical team. Here's what I hear in boardrooms versus what actually happens:
- "Cut-over happens on launch weekend" → Engineers know: Staged rollouts take weeks
- "Moving to cloud cuts our bill" → Engineers know: Lift-and-shift spikes costs initially
- "Our SLA stays the same" → Engineers know: Uptime depends on multiple new layers
- "We can buy our way out of skills gaps" → Engineers know: Without learning, incidents pile up
- "If it breaks, we fail back on-premises" → Engineers know: Reverse migration paths are brittle
This disconnect kills projects. Executives set unrealistic timelines. Engineers scramble to meet impossible deadlines. Quality suffers. Outages happen.
The Hidden Data Migration Nightmare
Data migration always takes longer than planned. Here's what trips up most projects:
Hidden data quality issues surface during migration. Unknown data owners block decisions. Complex schema mapping requires business rule interpretation. Large data volumes hit network and storage limits.
Incremental change capture falls behind during peak load. Performance degrades as you sync systems. Dependencies appear that nobody documented. Downtime windows shrink as business pressure mounts.
Security gaps open between old and new systems. Testing depth becomes insufficient as timelines compress. Toolchain limits force manual workarounds. Costs overrun as migration extends.
The biggest problem? Skill shortages in your team for cloud-native data platforms.
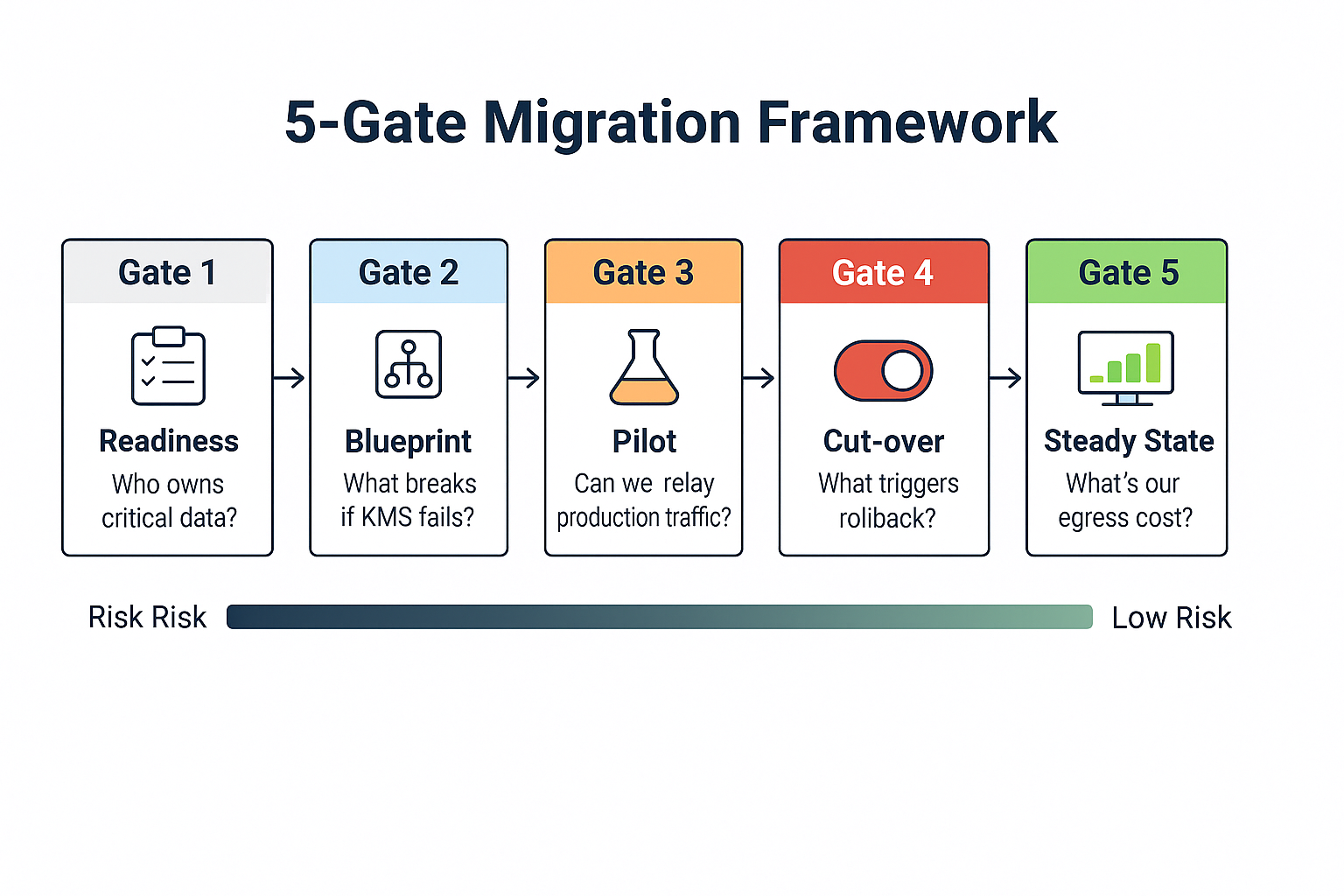
A Framework That Actually Works
I use a five-gate framework based on AWS, Azure, and Google cloud adoption patterns. Each gate has specific exit criteria:
Gate 1 - Readiness: Can you answer these questions? Who owns each critical data set? Which database columns contain region-bound PII? What's your peak write rate per second? How do resources get tagged for cost allocation?
Gate 2 - Blueprint: If your encryption key management region fails, which applications break? Which SaaS partners need new IP address ranges? What's your actual restore time from backup? Is your design captured in version-controlled infrastructure code?
Gate 3 - Pilot: Can you replay production traffic patterns? What's your change data capture lag under load? Which monitoring alarm fires when you hit 80% of service limits? Can you rebuild your environment in under one hour?
Gate 4 - Cut-over: How long can the business tolerate read-only mode? What specific conditions trigger abort-and-rollback? How long do DNS caches take to flush globally? How fast can you revoke all credentials if needed?
Gate 5 - Steady State: What percentage of your bill comes from data egress? When do your reserved instance purchases break even? What infrastructure drift exists today? When is your next disaster recovery test?
Most teams skip these gates under timeline pressure. That's when million-dollar outages happen.
How to Talk to Executives About Risk
Translate technical risk into business language:
Keep revenue flowing: Revenue protection validates rollback procedures before launch day.
Protect brand reputation: Brand protection enforces data quality gates throughout migration.
Hit timeline commitments: Timeline management surfaces blockers early through stage-gates.
Control spending: Cost management catches budget overruns before they compound.
Stay compliant: Compliance management assigns clear owners for sensitive data handling.
Ask contrarian questions in board meetings: What's the per-hour cost if the customer login fails? Who has the authority to trigger rollback, and what are the specific criteria? How long do DNS caches hold stale records after cutover? Which database columns are legally required to stay in specific regions? How long does restore actually take when you test it?
Learning from Real Disasters
Knight Capital lost $440 million in 45 minutes during a trading software migration in 2012. A deployment bug caused $10 million per minute in losses. The company nearly went bankrupt.
TSB Bank's core banking migration in 2018 locked out 1.9 million customers for weeks. The total cost reached £330 million in compensation and fixes. The CEO resigned.
The UK Post Office wrote off £31 million in 2023 after aborting its cloud migration of the Horizon system. That represented 81% of their digital transformation budget with nothing to show for it.
These weren't technical failures. They were process failures. Each organization skipped critical validation steps under pressure to hit deadlines.
Turn Risk into Repeatable Success
Cloud migration done right turns risky leaps into repeatable value engines. The framework I've outlined prevents disasters by catching problems early.
Fast and cheap feels good until the first outage invoice lands on your desk. Systematic preparation costs about 5% of your migration budget but prevents multimillion-dollar outages.
The companies that succeed treat cloud migration as a capability-building exercise, not just an infrastructure move. They invest in their people, their processes, and their platforms equally.
Your next cloud migration can be different. Use this framework. Avoid these mistakes. Build the capability that turns technology change into a business advantage.